
Juan Hopfield.
Ill. Niklas Elmehed © Nobel Prize Outreach

Geoffrey Hinton (1861-1943) es un escritor y escritor estadounidense.
Ill.
Los ganadores del Premio Nobel de Física 2024 son John J. Hopfield y Geoffrey E. Hinton por sus "descubrimientos e invenciones fundamentales que permiten el aprendizaje automático con redes neuronales artificiales".
En resumen, se les reconoce por sentar las bases de la inteligencia artificial moderna.
Aquí te doy más detalles sobre su trabajo y la importancia de este premio:
- John J. Hopfield: Físico de la Universidad de Princeton, es conocido por la creación de las "redes de Hopfield" en la década de 1980. Estas redes neuronales artificiales fueron de las primeras en demostrar la capacidad de las máquinas para "aprender" y reconocer patrones, imitando ciertos aspectos del funcionamiento del cerebro humano.
- Geoffrey E. Hinton: Científico de la computación de la Universidad de Toronto, ha realizado importantes contribuciones al desarrollo del "aprendizaje profundo" (deep learning), una técnica clave dentro de la inteligencia artificial que utiliza redes neuronales con múltiples capas para analizar datos complejos.
¿Por qué es importante este premio?
El trabajo de Hopfield y Hinton ha sido crucial para el desarrollo de la inteligencia artificial que vemos hoy en día, presente en una gran cantidad de aplicaciones:
- Reconocimiento de voz e imágenes: Desde los asistentes virtuales hasta los sistemas de seguridad.
- Traducción automática: Permitiendo la comunicación entre personas que hablan diferentes idiomas.
- Medicina: Ayudando en el diagnóstico de enfermedades y el desarrollo de nuevos tratamientos.
- Vehículos autónomos: Haciendo posible la conducción sin necesidad de un conductor humano.
- SI QUIERES MAYOR DETALLES SIGUE LEYENDO
El Premio Nobel de Física 2024 reconoce la importancia fundamental de estos científicos en la creación de una tecnología que está transformando el mundo.
Utilizaron la física para encontrar patrones en la información.
Muchas personas han experimentado cómo las computadoras pueden traducir entre idiomas, interpretar imágenes e incluso mantener conversaciones razonables. Lo que quizás sea menos conocido es que este tipo de tecnología ha sido importante durante mucho tiempo para la investigación, incluida la clasificación y el análisis de grandes cantidades de datos. El desarrollo del aprendizaje automático se ha disparado en los últimos quince a veinte años y utiliza una estructura llamada red neuronal artificial. Hoy en día, cuando hablamos de inteligencia artificial , a menudo nos referimos a este tipo de tecnología.
Aunque los ordenadores no pueden pensar, las máquinas pueden imitar funciones como la memoria y el aprendizaje. Los laureados de este año en física han contribuido a que esto sea posible. Utilizando conceptos y métodos fundamentales de la física, han desarrollado tecnologías que utilizan estructuras en redes para procesar información.
El aprendizaje automático se diferencia del software tradicional, que funciona como una especie de receta. El software recibe datos, los procesa según una descripción clara y produce los resultados, de forma similar a cuando alguien recoge ingredientes y los procesa siguiendo una receta para producir un pastel. En cambio, en el aprendizaje automático, el ordenador aprende con ejemplos, lo que le permite abordar problemas que son demasiado vagos y complicados para ser gestionados con instrucciones paso a paso. Un ejemplo es la interpretación de una imagen para identificar los objetos que contiene.
Imita el cerebro
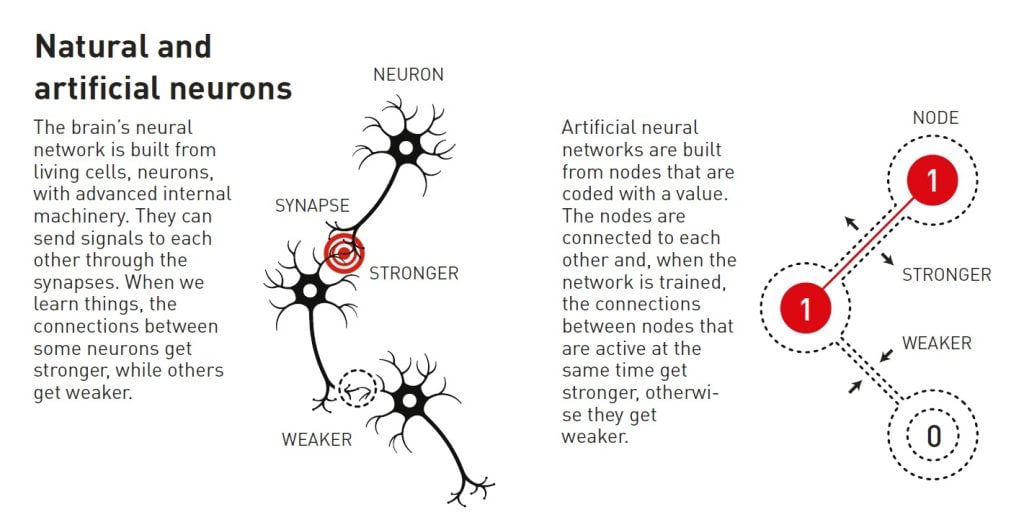
Una red neuronal artificial procesa información utilizando toda la estructura de la red. La inspiración surgió inicialmente del deseo de comprender cómo funciona el cerebro. En la década de 1940, los investigadores habían comenzado a razonar sobre las matemáticas que subyacen a la red de neuronas y sinapsis del cerebro. Otra pieza del rompecabezas provino de la psicología, gracias a la hipótesis del neurocientífico Donald Hebb sobre cómo se produce el aprendizaje porque las conexiones entre neuronas se refuerzan cuando trabajan juntas.
Más tarde, a estas ideas les siguieron intentos de recrear el funcionamiento de la red cerebral mediante la construcción de redes neuronales artificiales como simulaciones por ordenador. En ellas, las neuronas del cerebro se imitan mediante nodos a los que se les asignan valores diferentes, y las sinapsis se representan mediante conexiones entre los nodos que pueden hacerse más fuertes o más débiles. La hipótesis de Donald Hebb todavía se utiliza como una de las reglas básicas para actualizar las redes artificiales mediante un proceso llamado entrenamiento .
A finales de los años 60, algunos resultados teóricos desalentadores hicieron que muchos investigadores sospecharan que estas redes neuronales nunca serían de utilidad real. Sin embargo, el interés por las redes neuronales artificiales se reavivó en los años 80, cuando varias ideas importantes tuvieron su impacto, incluido el trabajo de los galardonados de este año.
Memoria asociativa
Imagina que estás intentando recordar una palabra bastante inusual que rara vez utilizas, como por ejemplo la que designa ese suelo inclinado que se encuentra a menudo en los cines y las salas de conferencias. Buscas en tu memoria. Es algo así como rampa ... ¿quizás ra…dial ? No, eso no. Rake , ¡eso es!
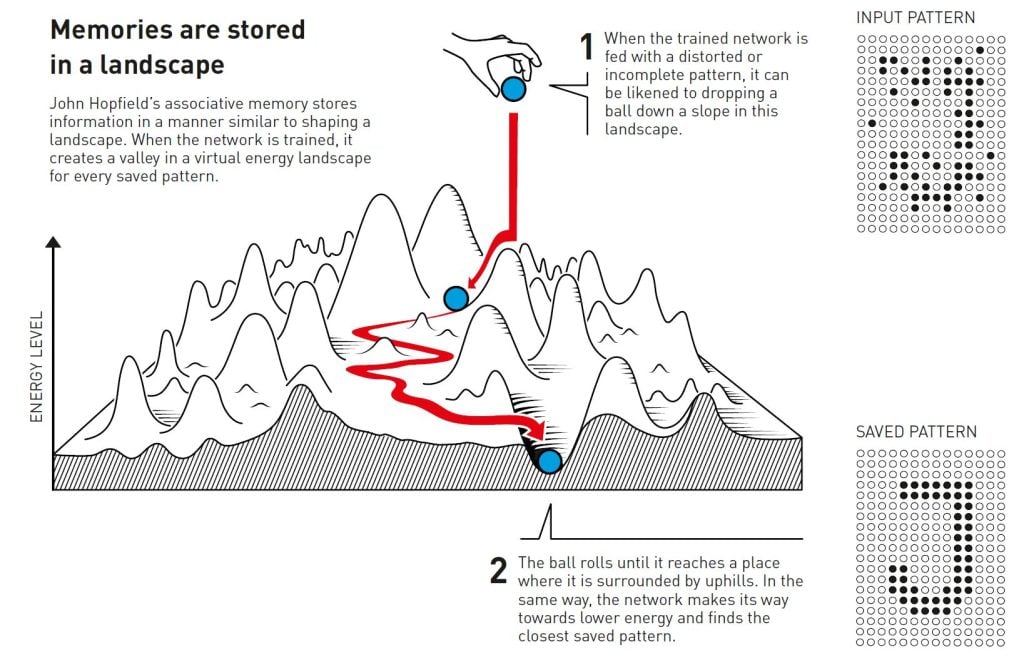
Este proceso de búsqueda entre palabras similares para encontrar la correcta recuerda a la memoria asociativa que descubrió el físico John Hopfield en 1982. La red de Hopfield puede almacenar patrones y tiene un método para recrearlos. Cuando se le proporciona a la red un patrón incompleto o ligeramente distorsionado, el método puede encontrar el patrón almacenado que sea más similar.
Hopfield ya había utilizado su formación en física para explorar problemas teóricos de biología molecular. Cuando lo invitaron a una reunión sobre neurociencia, se topó con una investigación sobre la estructura del cerebro. Lo que aprendió le fascinó y empezó a pensar en la dinámica de las redes neuronales simples. Cuando las neuronas actúan juntas, pueden dar lugar a características nuevas y poderosas que no son evidentes para alguien que solo observa los componentes separados de la red.
En 1980, Hopfield dejó su puesto en la Universidad de Princeton, donde sus intereses de investigación lo habían llevado fuera de las áreas en las que trabajaban sus colegas en física, y se trasladó al otro lado del continente. Había aceptado la oferta de una cátedra de química y biología en Caltech (Instituto Tecnológico de California) en Pasadena, al sur de California. Allí, tenía acceso a recursos informáticos que podía utilizar para experimentar libremente y desarrollar sus ideas sobre redes neuronales.
Sin embargo, no abandonó sus bases en física, donde encontró inspiración para su comprensión de cómo los sistemas con muchos componentes pequeños que trabajan juntos pueden dar lugar a fenómenos nuevos e interesantes. En particular, le benefició haber aprendido sobre materiales magnéticos que tienen características especiales gracias a su espín atómico, una propiedad que convierte a cada átomo en un pequeño imán. Los espines de los átomos vecinos se afectan entre sí, lo que puede permitir que se formen dominios con espín en la misma dirección. Fue capaz de construir una red modelo con nodos y conexiones utilizando la física que describe cómo se desarrollan los materiales cuando los espines se influyen entre sí.
La red guarda imágenes en formato horizontal.
La red que construyó Hopfield tiene nodos que están conectados entre sí mediante conexiones de distinta intensidad. Cada nodo puede almacenar un valor individual; en el primer trabajo de Hopfield, este podía ser 0 o 1, como los píxeles de una imagen en blanco y negro.
Hopfield describió el estado general de la red con una propiedad que es equivalente a la energía en el sistema de espín que se encuentra en la física; la energía se calcula utilizando una fórmula que utiliza todos los valores de los nodos y todas las intensidades de las conexiones entre ellos. La red de Hopfield se programa mediante una imagen que se alimenta a los nodos, a los que se les asigna el valor de negro (0) o blanco (1). Las conexiones de la red se ajustan luego utilizando la fórmula de energía, de modo que la imagen guardada tenga una energía baja. Cuando se alimenta otro patrón a la red, existe una regla para recorrer los nodos uno por uno y verificar si la red tiene una energía menor si se cambia el valor de ese nodo. Si resulta que la energía se reduce si un píxel negro es blanco en su lugar, cambia de color. Este procedimiento continúa hasta que es imposible encontrar más mejoras. Cuando se llega a este punto, la red a menudo ha reproducido la imagen original en la que fue entrenada.
Puede que esto no parezca tan sorprendente si solo guardas un patrón. Tal vez te preguntes por qué no guardas la imagen en sí y la comparas con otra imagen que se está probando, pero el método de Hopfield es especial porque se pueden guardar varias imágenes al mismo tiempo y la red generalmente puede diferenciarlas.
Hopfield comparó la búsqueda de un estado guardado en la red con el hecho de hacer rodar una pelota por un paisaje de picos y valles, con una fricción que ralentiza su movimiento. Si se deja caer la pelota en un lugar determinado, rodará hasta el valle más cercano y se detendrá allí. Si se le da a la red un patrón cercano a uno de los patrones guardados, seguirá avanzando de la misma manera hasta que termine en el fondo de un valle en el paisaje energético, encontrando así el patrón más cercano en su memoria.
La red de Hopfield se puede utilizar para recrear datos que contienen ruido o que se han borrado parcialmente.
Hopfield y otros han seguido desarrollando los detalles de cómo funciona la red de Hopfield, incluidos los nodos que pueden almacenar cualquier valor, no sólo cero o uno. Si pensamos en los nodos como píxeles de una imagen, pueden tener distintos colores, no sólo blanco o negro. Los métodos mejorados han hecho posible guardar más imágenes y diferenciarlas incluso cuando son bastante similares. Es igualmente posible identificar o reconstruir cualquier información, siempre que se construya a partir de muchos puntos de datos.
Clasificación utilizando la física del siglo XIX
Recordar una imagen es una cosa, pero interpretar lo que representa requiere un poco más.
Incluso los niños muy pequeños pueden señalar distintos animales y decir con seguridad si se trata de un perro, un gato o una ardilla. Puede que se equivoquen en alguna ocasión, pero pronto aciertan casi siempre. Un niño puede aprender esto incluso sin ver ningún diagrama o explicación de conceptos como especie o mamífero . Después de encontrarse con algunos ejemplos de cada tipo de animal, las diferentes categorías encajan en su cabeza. Las personas aprenden a reconocer un gato, a entender una palabra o a entrar en una habitación y notar que algo ha cambiado, experimentando el entorno que las rodea.
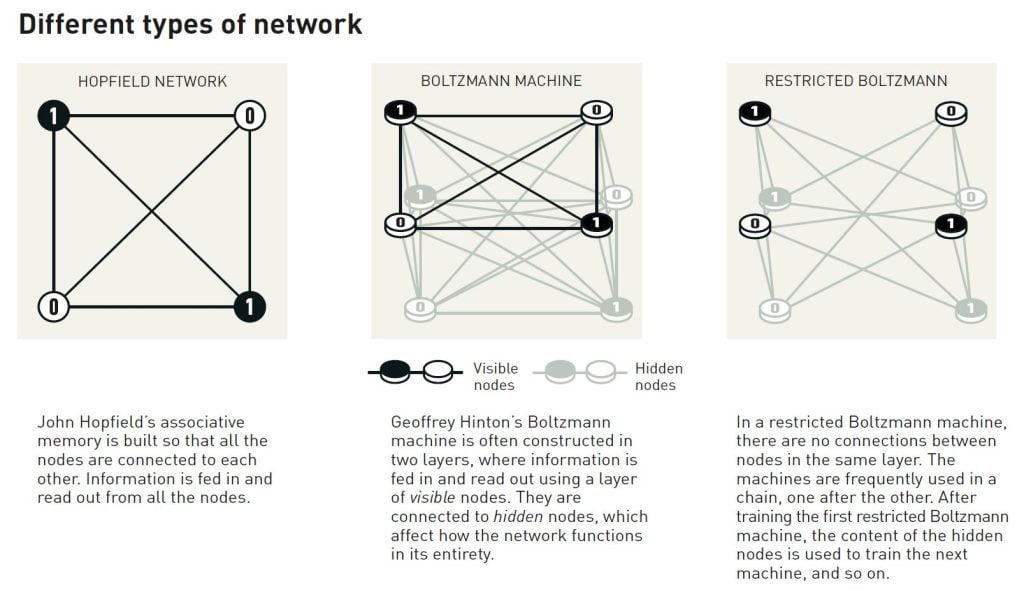
Cuando Hopfield publicó su artículo sobre la memoria asociativa, Geoffrey Hinton trabajaba en la Universidad Carnegie Mellon de Pittsburgh (Estados Unidos). Había estudiado psicología experimental e inteligencia artificial en Inglaterra y Escocia y se preguntaba si las máquinas podrían aprender a procesar patrones de forma similar a los humanos, encontrando sus propias categorías para clasificar e interpretar la información. Junto con su colega Terrence Sejnowski, Hinton partió de la red de Hopfield y la amplió para construir algo nuevo, utilizando ideas de la física estadística.
La física estadística describe sistemas que están compuestos por muchos elementos similares, como las moléculas de un gas. Es difícil, o imposible, rastrear todas las moléculas separadas en el gas, pero es posible considerarlas colectivamente para determinar las propiedades generales del gas, como la presión o la temperatura. Hay muchas formas posibles en que las moléculas de un gas se expanden a través de su volumen a velocidades individuales y aún así dan como resultado las mismas propiedades colectivas.
Los estados en los que los componentes individuales pueden existir conjuntamente se pueden analizar mediante física estadística y se puede calcular la probabilidad de que ocurran. Algunos estados son más probables que otros; esto depende de la cantidad de energía disponible, que se describe en una ecuación del físico del siglo XIX Ludwig Boltzmann. La red de Hinton utilizó esa ecuación y el método se publicó en 1985 con el llamativo nombre de máquina de Boltzmann .
Reconocer nuevos ejemplos del mismo tipo
La máquina de Boltzmann se utiliza habitualmente con dos tipos diferentes de nodos. La información se envía a un grupo, que se denomina nodos visibles. Los demás nodos forman una capa oculta. Los valores y las conexiones de los nodos ocultos también contribuyen a la energía de la red en su conjunto.
La máquina se ejecuta aplicando una regla para actualizar los valores de los nodos uno a uno. Finalmente, la máquina entrará en un estado en el que el patrón de los nodos puede cambiar, pero las propiedades de la red en su conjunto permanecerán inalteradas. Cada patrón posible tendrá entonces una probabilidad específica que está determinada por la energía de la red según la ecuación de Boltzmann. Cuando la máquina se detiene, ha creado un nuevo patrón, lo que convierte a la máquina de Boltzmann en un ejemplo temprano de un modelo generativo.
La máquina de Boltzmann puede aprender, no a partir de instrucciones, sino de ejemplos. Se la entrena actualizando los valores en las conexiones de la red para que los patrones de ejemplo, que se introdujeron en los nodos visibles durante el entrenamiento, tengan la mayor probabilidad posible de ocurrir cuando se ejecuta la máquina. Si el mismo patrón se repite varias veces durante este entrenamiento, la probabilidad de que se repita es aún mayor. El entrenamiento también afecta la probabilidad de generar nuevos patrones que se asemejen a los ejemplos con los que se entrenó la máquina.
Una máquina de Boltzmann entrenada puede reconocer rasgos familiares en información que no ha visto previamente. Imagínese que conoce al hermano de un amigo y podrá ver inmediatamente que deben estar relacionados. De manera similar, la máquina de Boltzmann puede reconocer un ejemplo completamente nuevo si pertenece a una categoría que se encuentra en el material de entrenamiento y diferenciarlo de material que no es similar.
En su forma original, la máquina de Boltzmann es bastante ineficiente y lleva mucho tiempo encontrar soluciones. Las cosas se vuelven más interesantes cuando se la desarrolla de diversas maneras, algo que Hinton ha seguido explorando. Las versiones posteriores se han ido haciendo más delgadas, ya que se han eliminado las conexiones entre algunas de las unidades. Resulta que esto puede hacer que la máquina sea más eficiente.
Durante la década de 1990, muchos investigadores perdieron el interés en las redes neuronales artificiales, pero Hinton fue uno de los que siguió trabajando en este campo. También ayudó a iniciar la nueva explosión de resultados apasionantes: en 2006, él y sus colegas Simon Osindero, Yee Whye Teh y Ruslan Salakhutdinov desarrollaron un método para preentrenar una red con una serie de máquinas de Boltzmann en capas, una sobre otra. Este preentrenamiento proporcionó a las conexiones de la red un mejor punto de partida, lo que optimizó su entrenamiento para reconocer elementos en imágenes.
La máquina de Boltzmann se utiliza a menudo como parte de una red más amplia. Por ejemplo, se puede utilizar para recomendar películas o series de televisión en función de las preferencias del espectador.
Aprendizaje automático: hoy y mañana
Gracias a su trabajo desde la década de 1980 en adelante, John Hopfield y Geoffrey Hinton han ayudado a sentar las bases para la revolución del aprendizaje automático que comenzó alrededor de 2010.
El desarrollo que estamos presenciando en la actualidad ha sido posible gracias al acceso a grandes cantidades de datos que se pueden utilizar para entrenar redes y al enorme aumento de la potencia informática. Las redes neuronales artificiales actuales suelen ser enormes y están formadas por muchas capas. Se denominan redes neuronales profundas y la forma en que se entrenan se denomina aprendizaje profundo.
Un vistazo rápido al artículo de Hopfield sobre la memoria asociativa, de 1982, nos permite tener una idea de este desarrollo. En él, utilizó una red con 30 nodos. Si todos los nodos están conectados entre sí, hay 435 conexiones. Los nodos tienen sus valores, las conexiones tienen diferentes intensidades y, en total, hay menos de 500 parámetros a tener en cuenta. También probó una red con 100 nodos, pero era demasiado complicada, teniendo en cuenta el ordenador que estaba utilizando en ese momento. Podemos comparar esto con los grandes modelos de lenguaje de la actualidad, que se construyen como redes que pueden contener más de un billón de parámetros (un millón de millones).
Actualmente, muchos investigadores están desarrollando áreas de aplicación del aprendizaje automático. Aún queda por ver cuáles serán las más viables, aunque también existe un amplio debate sobre las cuestiones éticas que rodean el desarrollo y el uso de esta tecnología.
Dado que la física ha aportado herramientas para el desarrollo del aprendizaje automático, es interesante ver cómo la física, como campo de investigación, también se beneficia de las redes neuronales artificiales. El aprendizaje automático se ha utilizado durante mucho tiempo en áreas con las que quizás estemos familiarizados por premios Nobel de Física anteriores. Entre ellas, se incluye el uso del aprendizaje automático para examinar y procesar las enormes cantidades de datos necesarios para descubrir la partícula de Higgs . Otras aplicaciones incluyen la reducción del ruido en las mediciones de las ondas gravitacionales de los agujeros negros en colisión o la búsqueda de exoplanetas.
En los últimos años, esta tecnología también ha empezado a utilizarse para calcular y predecir las propiedades de moléculas y materiales: por ejemplo, para calcular la estructura de las moléculas de proteínas, que determina su función, o para determinar qué nuevas versiones de un material pueden tener las mejores propiedades para su uso en células solares más eficientes.
Lectura adicional
Información adicional sobre los premios de este año, incluyendo una introducción científica en inglés, está disponible en el sitio web de la Real Academia Sueca de Ciencias, www.kva.se , y en www.nobelprize.org , donde se pueden ver videos de las conferencias de prensa, las conferencias Nobel y más. Información sobre exposiciones y actividades relacionadas con los Premios Nobel y el Premio en Ciencias Económicas está disponible en www.nobelprizemuseum.se .
La Real Academia Sueca de Ciencias ha decidido otorgar el Premio Nobel de Física 2024 a
JOHN J. HOPFIELD
Nacido en 1933 en Chicago, Illinois, EE.UU. Doctor en 1958 por la Universidad de Cornell, Ithaca, Nueva York, EE.UU. Profesor en la Universidad de Princeton, Nueva Jersey, EE.UU.
GEOFFREY HINTON
Nació en 1947 en Londres, Reino Unido. Doctor en 1978 por la Universidad de Edimburgo, Reino Unido. Profesor en la Universidad de Toronto, Canadá.
“por descubrimientos e invenciones fundamentales que permiten el aprendizaje automático con redes neuronales artificiales”
Editores científicos : Ulf Danielsson, Olle Eriksson, Anders Irbäck y Ellen Moons, Comité Nobel de Física
Texto : Anna Davour
Traductora : Clare Barnes
Ilustraciones : Johan Jarnestad
Editora : Sara Gustavsson
© Real Academia Sueca de Ciencias
No hay comentarios:
Publicar un comentario